简介
并发是一种程序计算的形式,
它可以使多个任务看起来像是同时在运行。
并发的应用很多,如网站同时应对多个请求、 GUI 的前端用户操作和后台的计算同步,
实际上并发是多个任务在交替运行,这样可以利用一个操作运行后的「等待期」来执行其他操作。
一个容易理解的例子是在网络传输的延迟时间段中执行其他运算,这样可以提高 CPU 的利用率。
与并行的区别
并行也是使计算机同时执行多个任务的一种方式,但是与并发不同的是,并行的任务不是交替执行的,而是在不同的 CPU 上运行。
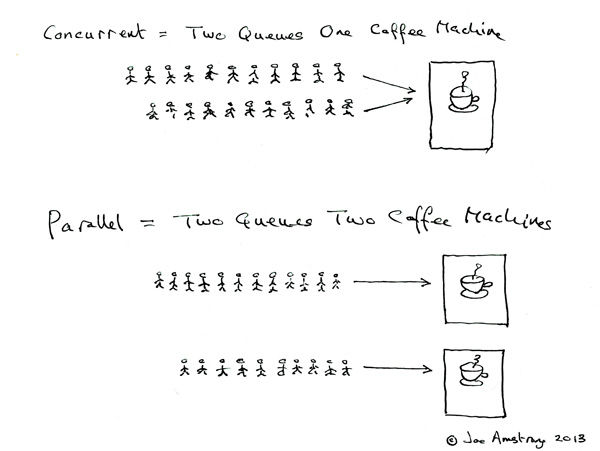
并发是两队人交替使用同一台机器,并行则是两队人使用不同的机器。我们可以粗浅地认为并发对于资源的要求更小,利用率更高,而并行的效率更高。
竞争
不过由于它的各个任务的不同指令的运行顺序是随机的,所以在设计难度上较高。
设计并发程序最大的挑战,在于确保不同运算运行步骤间的交互或是通信,能以正确的顺序进行,同时,也要确保在不同运行步骤间共享的资源,能够正确被访问。
例子
如对于下面的一个例子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
public class App implements Runnable {
public static int count = 0;
private static boolean lock = false;
private final int id;
public App(int id) {
this.id = id;
}
@Override
public void run() {
System.out.println(id + " " + ++count);
try {
Thread.sleep(id);
} catch (Exception e) {
e.printStackTrace();
} finally {
System.out.println(id + " " + ++count);
}
}
public static void main(String[] args) {
int n = 5;
App[] apps = new App[n];
for (int i = 0; i < n; ++i)
apps[i] = new App(i);
for (int i = n - 1; i >= 0; --i) {
new Thread(apps[i]).start();
}
System.out.println(App.count);
}
}
|
它在我的机器上的两次输出为(输出并不一定)
- Case 1
2 2
0 5
1 4
4 3
4
3 1
0 6
1 7
2 8
3 9
4 10
- Case 2
4 1
1
0 2
2 1
1 1
3 1
0 3
1 4
2 5
3 6
4 7
在这两次输出中,我们发现两次System.out.println(App.count);语句的输出结果在不同的位置,值也不同,还有一些Count值明明较大却较早输出等等现象。这都是因为在并发的程序中,不同的任务是交替运行的。
但是我们还发现第二次输出中Count的值似乎,没有到达10,但是直觉告诉我们Count必然在某个App中到达10.而且一些App的Count似乎相同,这显然是违反直觉的。
原子操作
我们引入一个概念:原子操作。类似于原子,我们可以理解一个原子操为一个不可分割的操作,在它运行时系统的其他部分不变。
当然原子是可以分割的,其实原子操作在其他方面,如汇编其实也可以分割。对于原子操作更深入的理解可以阅读关于线性一致性的文章。
需需要注意的是,一条语句不一定是一个原子操作,如我们可以将++count操作划分为三个原子操作:
- read count
- res = count + 1
- count = res
所以对于两个不同的App可能出现如下的现象:

此时会出现count虽然执行了两次++操作,但是实际上只增加了一的现象,我们将这种现象称为竞争,而五个App存在竞争关系。
这样我们就可以解释第二次输出的结果。
AtomicInteger
为了解决这个问题,我们可以将++count变为原子操作。此时我们可以使用 Java 自带的AtomicInteger类。它可以将一些操作变为原子操作,如将++count变为AtomicInteger.getAndIncrement()。
注意如果使用AtomicInteger.set(AtomicInteger.get() + 1),会和上述情况一样有并发问题,要使用AtomicInteger.getAndIncrement()才可以避免并发问题。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
import java.util.concurrent.atomic.AtomicInteger;
public class App implements Runnable {
public static AtomicInteger count = new AtomicInteger(0);
private final int id;
public App(int id) {
this.id = id;
}
@Override
public void run() {
System.out.println(id + " " + count.incrementAndGet());
try {
Thread.sleep(id);
} catch (Exception e) {
e.printStackTrace();
} finally {
System.out.println(id + " " + count.incrementAndGet());
}
}
public static void main(String[] args) {
int n = 5;
App[] apps = new App[n];
for (int i = 0; i < n; ++i)
apps[i] = new App(i);
for (int i = n - 1; i >= 0; --i) {
new Thread(apps[i]).start();
}
System.out.println(App.count);
}
}
|
此时我们运行的输出为:
3 2
4 3
5
0 5
1 4
2 1
0 6
1 7
2 8
3 9
4 10
锁和 synchronized
原子变量其实虽然简单,但是如果我们要让更多的代码具有原子性,那么就不行了。
所以我们需要使用其他的方法来实现,如使用一个boolean变量来强行让两次++count操作不会交替。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
public class App implements Runnable {
public static int count = 0;
private static boolean lock = false;
private final int id;
public App(int id) {
this.id = id;
}
private int increaseCount() {
while (lock)
continue;
lock = true;
int res = ++count;
lock = false;
return res;
}
@Override
public void run() {
System.out.println(id + " " + increaseCount());
try {
Thread.sleep(id);
} catch (Exception e) {
e.printStackTrace();
} finally {
System.out.println(id + " " + increaseCount());
}
}
public static void main(String[] args) {
int n = 5;
App[] apps = new App[n];
for (int i = 0; i < n; ++i)
apps[i] = new App(i);
for (int i = n - 1; i >= 0; --i) {
new Thread(apps[i]).start();
}
System.out.println(App.count);
}
}
|
此时输出为:
1 4
3 3
2
2 2
4 1
0 5
0 6
1 7
2 8
3 9
4 10
这其实是一种简单地实现Java自带的synchronized,我们的实现十分简陋。
Java程序使用synchronized关键字对一个对象进行加锁,保证一段代码的原子性就是通过加锁和解锁实现的,其代码格式如下:
1
2
3
|
synchronized(lock) { // 获取锁
...
} // 释放锁
|
我们就可以将上述代码改为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
public class App implements Runnable {
public static int count = 0;
private static Object lock = new Object();
private final int id;
public App(int id) {
this.id = id;
}
private int increaseCount() {
int res;
synchronized(lock) {
res = ++count;
}
return res;
}
@Override
public void run() {
System.out.println(id + " " + increaseCount());
try {
Thread.sleep(id);
} catch (Exception e) {
e.printStackTrace();
} finally {
System.out.println(id + " " + increaseCount());
}
}
public static void main(String[] args) {
int n = 5;
App[] apps = new App[n];
for (int i = 0; i < n; ++i)
apps[i] = new App(i);
for (int i = n - 1; i >= 0; --i) {
new Thread(apps[i]).start();
}
System.out.println(App.count);
}
}
|
使用synchronized解决了多线程同步访问共享变量的正确性问题。但是,它的缺点是带来了性能下降。因为synchronized代码块无法并发执行。此外,加锁和解锁需要消耗一定的时间,所以,synchronized会降低程序的执行效率。
我们来概括一下如何使用synchronized:
- 找出修改共享变量的线程代码块
- 选择一个共享实例作为锁
- 使用
synchronized(lockObject) { ... }
而且使用synchronized的时候,不必担心抛出异常。因为无论是否有异常,都会在synchronized结束处正确释放锁。
同步方法
对于一个类的方法,我们可以添加synchronized关键字使得整个方法是都加锁,而锁定的实例就是自身this。
即
1
2
3
|
public synchronized void foo() {
...
}
|
等价于
1
2
3
4
5
|
public void foo() {
synchronized(this) {
...
}
}
|
而对于静态方法,锁定的为该的Class实例Class.class。